5.1 Beneficial and Harmful effects homework
I believe that artificial intelligence is both beneficial and harmful, but its misuse can be especially damaging. While AI can improve efficiency and accuracy in fields like healthcare and transportation, it also poses risks, such as privacy violations and job displacement. In San Diego, companies using AI for data collection may unintentionally compromise personal information, highlighting the need for stronger data protection policies. Additionally, over-reliance on AI in hiring processes can reinforce biases, making it harder for marginalized groups to access job opportunities. To prevent these harmful effects, it’s important to advocate for responsible AI regulations and promote ethical development practices.
Digital Divide
In San Diego, I’ve noticed that students from lower-income neighborhoods, like Southeast San Diego, often have limited access to personal laptops or stable internet connections, making it harder for them to complete schoolwork efficiently. Some areas lack public resources, such as libraries with reliable free Wi-Fi, leaving families without home internet disconnected. During remote learning, students with outdated devices struggled with slow performance, while those with newer technology had a clear advantage. I’ve also seen how older adults, especially in underserved areas, lack the digital skills needed to access essential services, like healthcare portals or job applications. To help bridge this gap, I can volunteer with local programs by teaching digital literacy or helping distribute refurbished devices to families in need.
Computing Bias
Popcorn hack #1: B since you are explicitly providing the user data about your name and other information
Popcorn hack #2: B since a system trained on an underrepresented dataset, such as people with darker skin tones, leads to poor performance for those groups, illustrating Data Bias.
Popcorn hack #3: Unintentional bias happens when someone unknowingly favors one group over another. For example, a teacher might call on boys more often than girls without meaning to, simply because of unconscious habits or assumptions.
Short Answer Question:
Implicit data is information collected indirectly from user behavior without the user explicitly stating preferences. For example, an online retailer tracking the items you browse or purchase over time infers your interests.
Explicit data is information that a user provides directly, such as filling out a survey or rating a product. For instance, when you rate a movie on a streaming service, you’re giving explicit feedback.
Crowdsourcing
Popcorn hack #1
Crowd Funding: People contribute money to support projects, helping innovators bring ideas to market (e.g., Kickstarter).
Crowd Creation: The crowd collaboratively creates content, products, or solutions, fostering collective innovation (e.g., Wikipedia).
Crowd Voting: Public votes or provides feedback, guiding decisions and highlighting popular ideas (e.g., Reddit upvotes).
Crowd Wisdom: The crowd shares knowledge or insights, solving problems through collective intelligence (e.g., Waze traffic updates).
Popcorn hack #2
Data crowdsourcing gathers large datasets through public contributions, boosting diversity, speed, and collaboration in open-source development.
Examples of Crowdsourced Datasets:
ImageNet: 14M+ labeled images for AI training.
Common Voice: Mozilla’s open-source voice dataset.
OpenStreetMap: Crowdsourced geographic data.
Popcorn hack #3
Distributed computing uses volunteers' devices to process massive datasets, speeding up research and innovation.
Examples of Successful Projects:
SETI@home: Searches for extraterrestrial signals.
Folding@home: Simulates protein folding for disease research.
BOINC: Supports scientific projects with volunteer computing.
Homework
Crowdsourcing plays a vital role in today’s age by harnessing the collective skills, insights, and resources of large groups to solve problems and drive innovation. It takes many forms, including crowd funding to support new ventures, crowd creation for collaborative content, crowd voting to guide decisions, and crowd wisdom to solve complex issues. Distributed computing further enhances crowdsourcing by using volunteer devices to process large datasets, accelerating scientific research and data analysis. Meanwhile, data crowdsourcing fuels open-source development by providing diverse, real-world datasets for training AI models and building better applications.As technology advances, crowdsourcing holds immense potential to transform industries, from healthcare and AI to climate research, by enabling faster, more collaborative innovation.
Safe Computing
Homework Hack 2
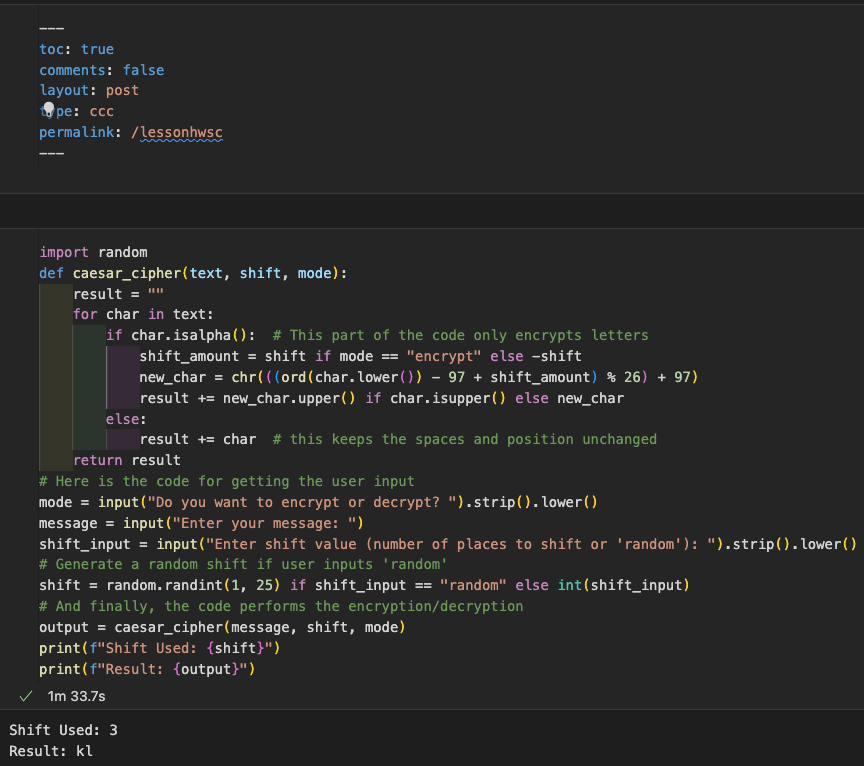
Lists and Filtering
Popcorn hack 1:
Lists are a versatile and efficient way to store multiple values in a single variable, allowing for easy access, manipulation, and iteration of data. They offer benefits like dynamic sizing, organized storage, and the ability to sort or filter items. Real-world examples of lists in code include to-do list apps, student grade tracking, inventory management, web scraping, and bank account transactions. Lists make handling collections of data simple, whether you're organizing tasks, calculating averages, or tracking changes over time.
Popcorn hack 2:
The code output is eraser
1. The list items is initially ["pen", "pencil", "marker", "eraser"].
2. items.remove("pencil") removes the item "pencil" from the list, so the list becomes ["pen", "marker", "eraser"].
3. items.append("sharpener") adds "sharpener" to the end of the list, so the list becomes ["pen", "marker", "eraser", "sharpener"].
4. print(items[2]) prints the element at index 2 in the list, which is "eraser".
Popcorn hack 3:
Filtering algorithms are used in many real-world applications to sort through large amounts of data and highlight what’s most relevant. For example, search engines filter results to show the most relevant pages based on a user's query, while social media platforms use filters to personalize content and ads for users. Email services use spam filters to block unwanted messages, and recommendation systems like Netflix or Amazon filter through catalogs to suggest movies, products, or shows based on user preferences. These algorithms improve efficiency and enhance user experience by focusing on what matters most.
Homework Hack
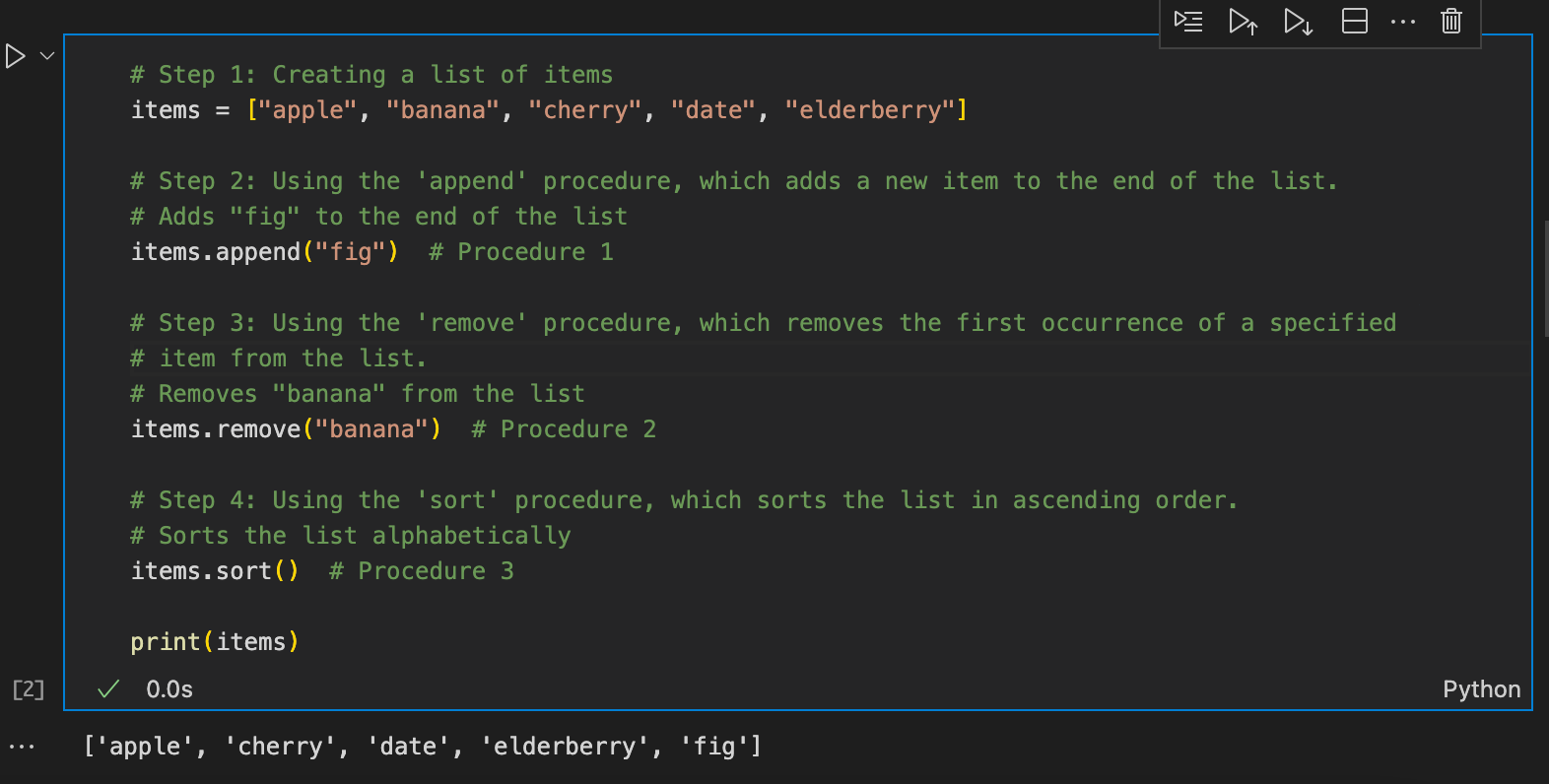
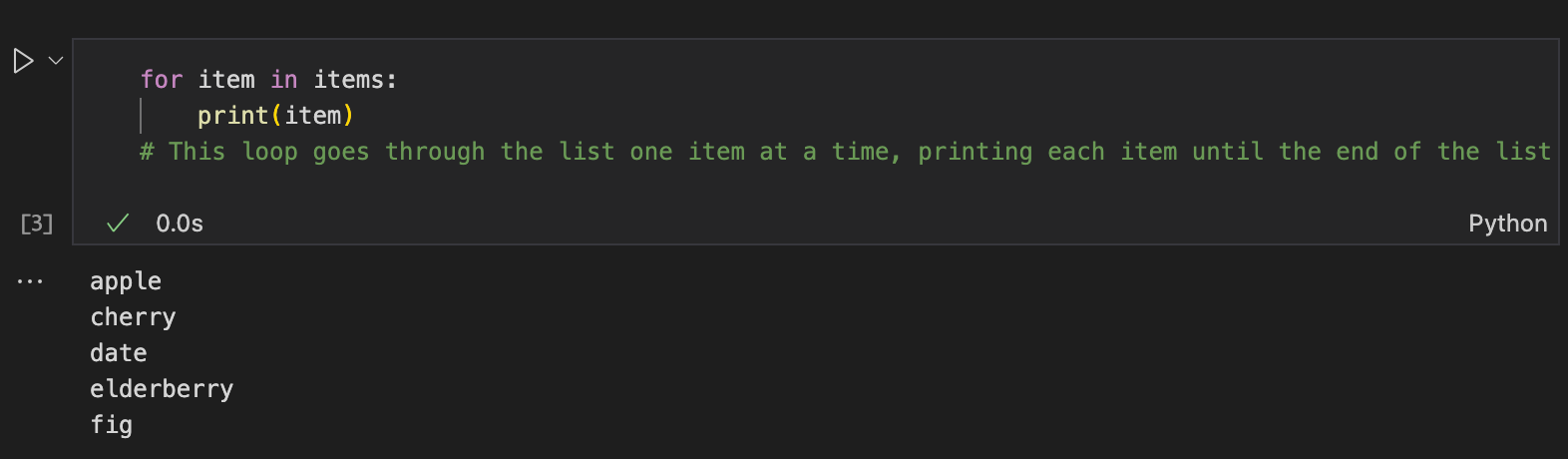
Steps to traverse the list:
Start with the first item in the list.
Use a loop (for loop) to iterate over each item in the list.
Access each item using the loop’s index or directly.
Perform any operation you need on the item (e.g., printing it, modifying it, etc.).
Continue to the next item in the list until all items have been processed.
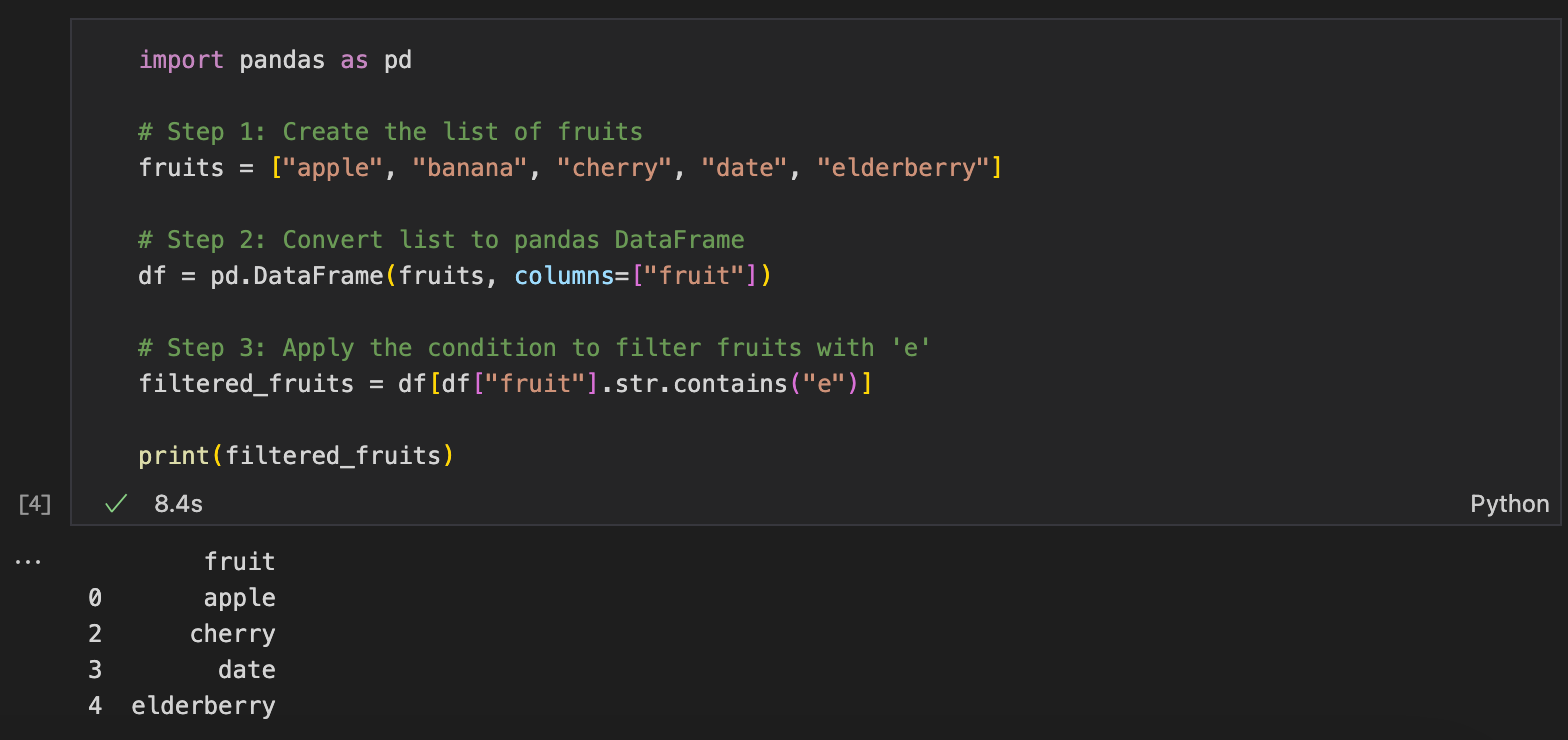
Filtering Algorithm (Using Pandas):
Condition: Filter for fruits that contain the letter 'e'
Steps:
Start with a list of items (fruits in this case).
Convert the list to a pandas DataFrame for better manipulation.
Use list traversal (looping) to check each item.
Apply the condition: check if the item contains the letter 'e'.
Build a new list containing only the items that meet the condition (i.e., contain 'e').
Final Reflection
Filtering algorithms and lists are used in real life to sort and refine data, such as when a search engine filters results based on relevance to a user's query. Lists help store and organize information, and filtering algorithms ensure only the relevant data is selected for display or further analysis.
Big O and Algorithmic Efficiency
Popcorn Hack 1
Best 2 strategies:
Use the modulus operator (%) to check if the remainder when divided by 2 is 0 and check if the last digit is 0, 2, 4, 6, or 8 manually
Explanation:
The modulus operator is the most efficient because it’s a direct math operation with constant time complexity O(1). Checking the last digit manually (if the number is a string or digit) is also quick and doesn't require loops or extra space.
Popcorn Hack 2
Time Complexity
Linear Search: O(n)
Binary Search: O(log n)
Sample Output
Linear search: 1.234567 seconds
Binary search: 0.000123 seconds
Binary search is approximately 10000x faster
What happens if data size is increased to 20,000,000?
Linear search takes about twice as long, since it goes through each item.
Binary search grows very slowly, only doing a few more checks (because it cuts the list in half each time).
Analysis
Choose the speed-optimized method for a performance-critical application because it runs much faster (O(n)) and handles large strings efficiently. The memory-optimized method is slower due to repeated insertions (O(n²)) and isn’t worth the small memory savings.
Homework hack 1
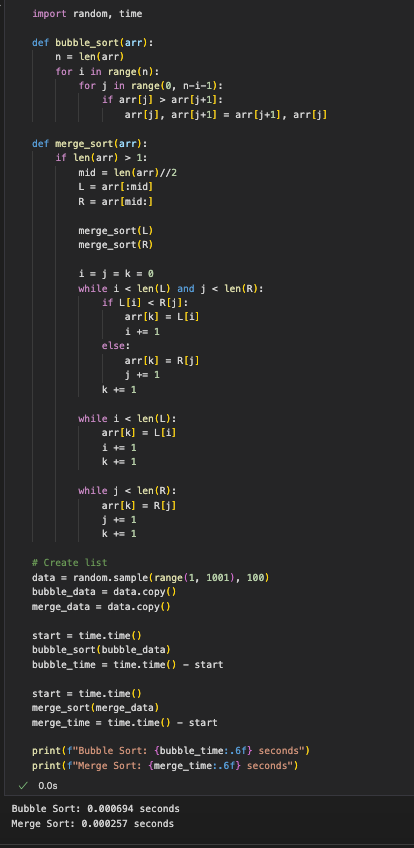
Why Merge Sort is faster
Merge sort consistently outperforms bubble sort because it divides the list into smaller parts and sorts them efficiently, making fewer total comparisons. Bubble sort repeatedly compares and swaps neighbors, which is much slower for large lists.
Homework hack 2
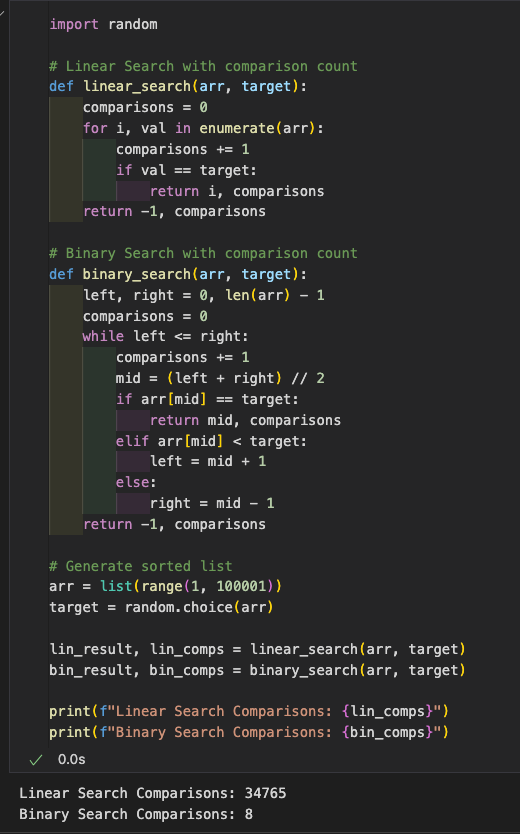
Which is faster and why?
Binary search is faster because it reduces the search space in half every step, while linear search checks every single number one by one.
What happens with an unsorted list?
Binary search won’t work properly on unsorted lists. It needs a sorted list to divide and conquer.Linear search still works fine on unsorted lists, though slower.
Undecidable Problems, graphs, and heuristics
popcorn hack
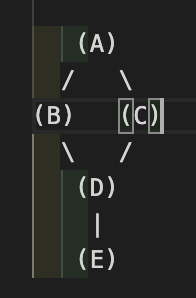
Cities: A, B, C, D, E
Roads (edges): AB, AC, BD, CD, DE
You can assign weights (distances) like: AB=5, AC=6, BD=3, CD=4, DE=2
Homework hack
Q1: C
Redundant routing = more than one path between two devices.
If Configuration I has only one path between Q and V → no redundancy.
If Configuration II has multiple paths (like via different routers or devices) → redundancy.
Q2: B
If T and U are connected through multiple paths, you’d need to break all of them.
If there’s only one path, breaking one connection is enough.
If there are two separate paths, you'd need to break both to disconnect T and U.
Popcorn hack 2
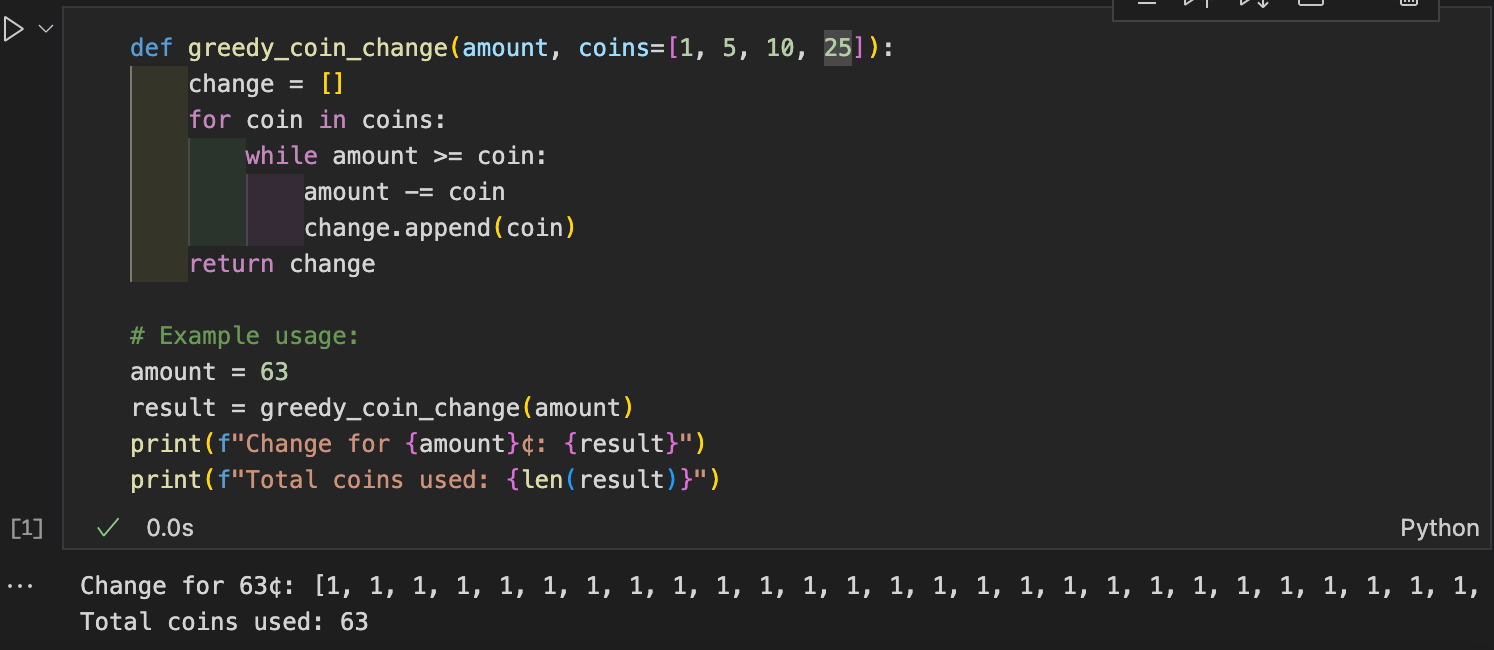
Reflection:
Less efficient when reversed, Not perfect, and Greedy is good enough for U.S. coins but fails with some other coin sets.
Homework hack 2
Changing the order of the coins made the algorithm less efficient, using many more coins when starting with the smallest values. The original greedy algorithm, which starts with the largest coin, used fewer coins overall. This shows that greedy algorithms work well when the coin system is designed to support it, but they can fail if the coin values don’t fit a simple pattern.
Base 2 Math and Logic Gates
Popcorn Hack 1: Identifying Binary
Example 1:
This is binary because it only has 1s and 0s.
Example 2:
This is NOT binary because it has digits (2 and 3) that are not 0 or 1.
Example 3:
This is binary because it only has 1s and 0s.
Popcorn Hack 2
Example 1:
101 + 110 = 1011
Example 2:
1101 - 1011
convert to decimal:
1101 → 13
1011 → 11
13 - 11 = 2
Convert 2 back to binary:
10
Example 3:
111 + 1001
Convert to decimal:
111 → 7
1001 → 9
7 + 9 = 16
Convert back to binary:
10000
Popcorn Hack 1
False and False → False
True or False → True
Answer: True
Popcorn Hack 2:
False and False → False
Answer: False
Popcorn Hack 3
not False → True
True or False and True
False and True → False Finally:
True or False → True
Homework Hack 1
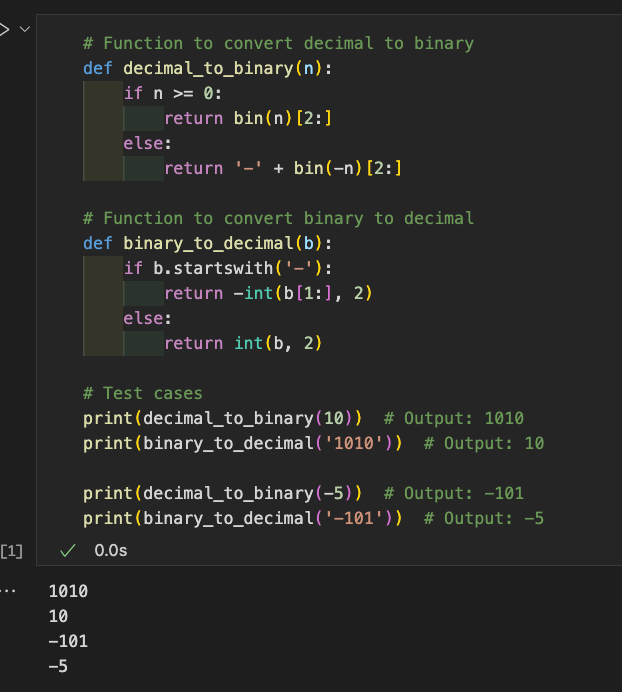
Homework Hack 2
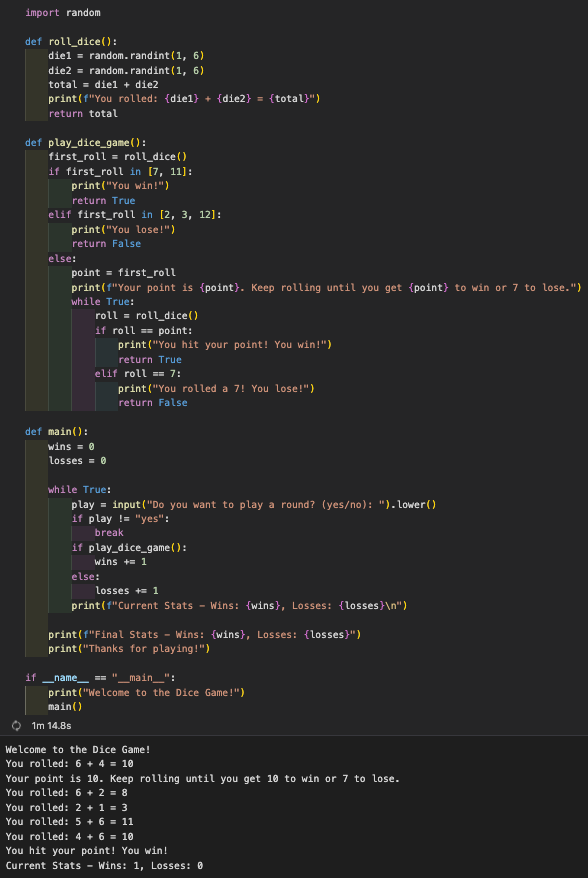
Stimulation/Games and Random Algorithims
Popcorn Hack 1
Cryptography – Random numbers are used to generate encryption keys, ensuring secure communication and data protection.
Video Game Development – Random numbers create unpredictable events, like enemy spawns or loot drops, making games more exciting and replayable.
Popcorn Hack 2
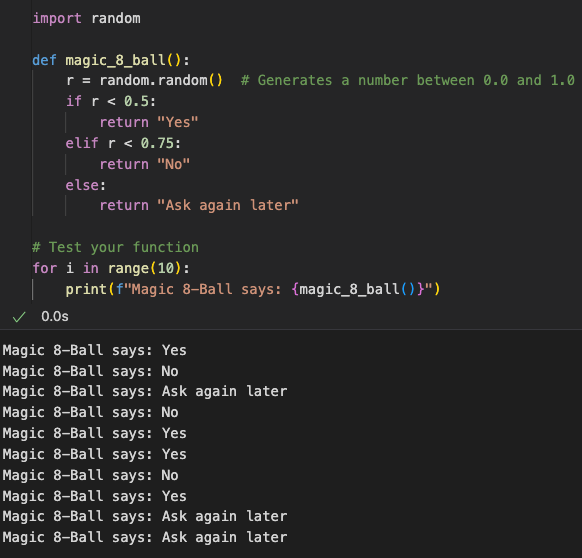
Popcorn Hack 3
This is a simulation because it mimics how a real traffic light cycles through signals over time. Its real-world impact is improving traffic flow and safety by helping engineers test timings before applying them to real intersections.
Homework Hack 1